(Pandas를 활용한 데이터 분석 문제) 목표: 공공데이터 포털에서 '따릉이' 데이터를 다운로드하여 Pandas를 사용해 데이터를 분석하고, 특정 조건에 맞는 정보를 추출하는 퀴즈 수행
데이터소스: 1. 공공데이터 포털에 접속 2. 검색창에 따릉이 검색 3. 검색 결과에서 첫번째로 나오는 엑셀파일 다운로드 4. df = pd.read_csv('bicycle.csv', encoding = 'cp949') 주요 작업: 1. Pandas를 사용하여 다운로드한 '따릉이' 데이터를 읽어들임 2. 다음과 같은 데이터 처리를 진행: - 대여소명에서 숫자를 제거하여 새로운 열에 저장 - 대여시간대를 '새벽' '아침' '점심' '저녁' '밤'으로 분류하여 새로운 열에 저장. (apply 함수 활용) 3. 생성된 새로운 열들을 이용하여 각 대여소명별로 가장 많은 대여가 일어난 시간대를 집계 (groupby와 value_counts 활용) 4. 신촌동의 [점심] 자전거 대여 수를 파이그래프로 나타내기
인터넷에 있는 웹페이지를 자동으로 탐색하고 정보를 수집하는 과정. 이를 수행하는 소프트웨어를 Crawler, 또는 Spider라고 함.
웹크롤링이 왜 필요한가? - 대량의 유용한 데이터 수집이 가능하고 - 웹사이트의 컨텐츠를 검색엔진에 인덱싱하여 최적화 가능 - 웹사이트 분석, 고객 리뷰 수집 등 시장조사에 활용 가능
HTML 태그 (Tags) - 웹 페이지의 기본 구성 요소 - <태그이름> 형식으로 작성되며, 대부분의 태그는 시작태그 와 종료 태그 로 구성됨 - 예)
는 단락 (paragraph)을 나타내는 태그
id 속성 - HTML 요소에 고유한 식별자를 제공 - 페이지 내에서 유일해야 하며, 주로 JAVASCRIPT나 CSS에서 요소를 식별할 때 사용됨 - 예)
는 'header"인 div 요소를 나타냄
class속성 - HTML요소에 하나 이상의 클래스를 지정 - 같은 스타일을 공유하는 여러 요소에 사용되며, CSS에서 스타일을 적용하거나 JAVASCRIPT에서 요소를 선택할 때 유용함 - 예) 는 "HIGHLIGHT" 클래스를 가진 span 요소로 나타냄
가장 많이 쓰이는 웹크롤링용 파이썬_라이브러리는 beautiufulsoup4
beautifulsoup4 사용법
from bs4 import BeautifulSoup
import requests
url = "https://finance.naver.com/sise/"
response = requests.get(url)
response.encoding = 'cp949'
print(response.text)
html = response.text
soup = BeautifulSoup(html,'html.parser')
itemList = soup.find(id = "popularItemList")
li_list = itemList.find_all('li')
stockList=[]
for i in li_list :
stockList.append({'company':i.find('a').text,'price':i.find('span').text})
print(stockList)
주요 메소드
1. find(): 특정 태그를 찾는 데 사용됨. 첫 번째로 발견된 해당 태그의 내용을 반환 2. find_all(): 특정태그를 모두 찾는 데 사용됨, 해당 태그가 여러개 있을 때 모든 결과를 리스트 형태로 반환함 3. get_text(): 태그 안의 텍스트 내용만을 추출 4. get(): 특정 속성의 값을 추출. 주로 링크나 이미지의 url을 가져오는 데 사용됨
판다스에서의 GroupBy 쉽게 이해하기 : 그룹화는 데이터를 쉽게 이해하기 위해 비슷한 특성을 가진 것들을 모으는 것 (ex. 학교에서 학생들을 '좋아하는 과목'에 따라 그룹으로 나눠 볼 수 있음) 판다스에서도 이런 그룹화가 가능하며, 만약 학생들의 데이터가 있고, '이름' '학년' '좋아하는 과목' 열이 있다면, '좋아하는 과목'을 기준으로 그룹화 할 수 있음. 이렇게 그룹화를 하면, 각 과목을 좋아하는 학생들의 평균 성적이나, 각 학년별로 어떤 과목이 인기 있는지 알아볼 수 있으며, 이런 분석을 통해 데이터에 숨겨진 패턴을 발견할 수 있음
(GroupBy 예시)
import pandas as pd
import random
from faker import Faker
faker = Faker ('ko_KR') #한글이름 랜덤 불러오기
# name, ages, genders, movies, payment methods, snacks, drinks, times
ageList = [20,30,40,50,60] #연령대 설정
agePercent = [30,30,20,15,5] #연령대 비율 설정
genderList = ['m','f']
movieList = ['웡카','시민덕희','도그맨','너의 이름은','외계인']
moviePercent = [40,10,5,5,40] #영화 시청률 설정
paymentsList = ['현금','체크카드','신용카드','카카오페이','네이버페이']
paymentsPercent = [5,30,35,20,10]
snackList = ['선택안함','일반','캬라멜','나초','오징어','맛밤']
snackPercent = [40,10,20,15,10,5]
drinkList = ['선택안함','콜라','제로콜라','물','에이드','스프라이트','오렌지주스']
drinkPercent = [30,10,20,10,10,15,5]
timeList = ['조조','일반','심야']
timePercent = [20,70,10]
data = {
'name': [faker.name() for i in range (500)],
# faker에서 이름을 500개 만들기
'ages':[random.choices(ageList, weights=agePercent, k=1) for i in range (500)],
# ageList에서 500개 랜덤 초이스 & agePercent가중치 적용하기, k=1은 결과의 첫번째를 뽑는걸로 설정
'genders': [genderList[random.randint(0,1)] for i in range(500)],
'movies': [random.choices(movieList, weights=moviePercent, k=1) for i in range (500)],
'payments': [random.choices(paymentsList, weights=paymentsPercent, k=1) for i in range (500)],
'snacks': [random.choices(snackList, weights=snackPercent, k=1) for i in range (500)],
'drinks': [random.choices(drinkList, weights=drinkPercent, k=1) for i in range (500)],
'times': [random.choices(timeList, weights=timePercent, k=1) for i in range (500)],
}
df = pd.DataFrame(data)
pd.read_csv('cgv.csv')
print(df.shape) #행과 열의 수
print(df.index) #행 정보
print(df.columns) #열 정보
print(df.values) #데이터
print(df.head(20)) #위에서 20개 가져오기
print(df.tail(20)) #뒤에서 20개 가져오기
print(df.describe()) #전체 데이터 요약본
# name ages genders movies payments snacks drinks times
#count 500 500 500 500 500 500 500 500
#unique 408 5 2 5 5 6 7 3
#top 김진호 [30] f [웡카] [신용카드] [선택안함] [선택안함] [일반]
#freq 5 160 260 205 169 190 161 359
#--------------------------
# group_by: 기준 잡기
#
group_by_movies = df.groupby('movies') # 영화별로 그룹핑
ages_group_by_movies = group_by_movies['ages'].value_counts()
print(ages_group_by_movies)
group_by_times = df.groupby('times')
print(group_by_times.value_counts())
drinks_group_by_times = group_by_times['drinks'].value_counts()
print(drinks_group_by_times)
#나이대별로 지불 그룹핑
group_by_ages = df.groupby('ages')
payments_group_by_ages = group_by_ages['payments'].value_counts()
print(payments_group_by_ages)
#영화별로 스낵 그룹핑
group_by_movies = df.groupby('movies')
snacks_group_by_movies = group_by_movies['snacks'].value_counts()
print(snacks_group_by_movies)
#시간대별로 영화 그룹핑
group_by_times = df.groupby('times')
movies_group_by_times = group_by_times['movies'].value_counts()
print(movies_group_by_times)
판다스 (Pandas) Apply 함수
판다스에서의 Apply 함수 쉽게 이해하기 : 판다스의 DataFrame에서 'apply'함수를 사용하면, 사용자가 정의한 함수를 각 행이나 열에 적용할 수 있음. 예를 들어, 학생들의 성적 데이터가 있고 '수학' '영어' '과학' 열이 있다면, 각 학생의 평균 성적을 계산하기 위해 apply 함수를 사용할 수 있음. 이렇게 apply 함수를 활용하면, 데이터셋의 각 행이나 열에 복잡한 연산을 쉽고 빠르게 적용할 수 있음. 또한, 이를 통해 데이터를 더 깊이 분석하고 의미있는 인사이트를 얻을 수 있음. 이러한 분석은 데이터를 더 효과적으로 이해하고 활용하는 데 도움이 됨.
(Apply함수 예시)
import pandas as pd
# apply : 새로운 열 만들기
df = pd.read_csv('cgv.csv')
def recommendPopcornForSenior(row):
if row['ages']==50 and row['snacks']=='일반':
return '할인 대상'
else:
return '할인 없음'
# name ages genders movies ... snacks drinks times 50대 할인 이벤트
#0 이예은 [30] f ['외계인'] ... ['캬라멜'] ['제로콜라'] ['일반'] 할인 없음
#1 김영식 [30] f ['시민덕희'] ... ['일반'] ['선택안함'] ['조조'] 할인 없음
#2 박도현 [50] m ['외계인'] ... ['선택안함'] ['스프라이트'] ['일반'] 할인 없음
#3 배지훈 [30] m ['외계인'] ... ['나초'] ['선택안함'] ['일반'] 할인 없음
#4 이명숙 [60] m ['너의 이름은'] ... ['선택안함'] ['선택안함'] ['일반'] 할인 없음
#.. ... ... ... ... ... ... ... ... ...
#조조이고 체크카드를 사용하면 조조이벤트 해당됨, 해당안됨
def morningEvent(row):
if row['times']=='조조' and row ['payments'] == '체크카드':
return '해당됨'
else:
return '해당안됨'
def comboEvent(row):
if row['snacks']=='일반' and row ['drinks'] == '제로콜라':
return '제로콤보 세트'
else:
return '해당없음'
df['제로이벤트'] = df.apply(comboEvent,axis=1)
df['50대 할인 이벤트'] = df.apply(recommendPopcornForSenior,axis=1)
df['조조이벤트'] = df.apply(morningEvent,axis=1)
print(df)
# name ages genders movies ... times 제로이벤트 50대 할인 이벤트 조조이벤트
#0 이예은 [30] f ['외계인'] ... ['일반'] 해당없음 할인 없음 해당안됨
#1 김영식 [30] f ['시민덕희'] ... ['조조'] 해당없음 할인 없음 해당안됨
#2 박도현 [50] m ['외계인'] ... ['일반'] 해당없음 할인 없음 해당안됨
#3 배지훈 [30] m ['외계인'] ... ['일반'] 해당없음 할인 없음 해당안됨
#4 이명숙 [60] m ['너의 이름은'] ... ['일반'] 해당없음 할인 없음 해당안됨
#
판다스 (Pandas) 데이터 시각화
Matplotlib 라이브러리
데이터 범주형
일변량 그래프
이변량 그래프
다변량 그래프
(일변량그래프 예시)
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('cgv.csv')
snacks_by_times = df.groupby('times')['snacks'].value_counts()
morning_time_snack = snacks_by_times['조조']
plt.rcParams['font.family'] = 'Malgun Gothic' #폰트 설정
morning_time_snack.plot.pie(autopct = '%1.1f%%') # plot.pie() 파이그래프, autopct = 소수점자리 설정
plt.show() # 보여주기
(REVIEW 1) 주어진 배열에 포함된 각 문자열의 길이를 카운트하고, 각 길이가 배열 내에서 몇 번 나타나는지를 계산하는 함수 작성하기. 함수는 배열을 입력으로 받고, 각 문자열 길이를 키로하고 해당 길이가 나타나는 횟수를 값으로 하는 딕셔너리를 반환해야 함. 입력 : {"apple","banana","cherry","date"} 출력: {5:2, 6:1, 4:1}
추가 지시사항: 1. 함수의 이름은 solution으로 한다 2. 입력 배열은 문자열만 포함한다고 가정한다 3. 배열 내에 중복된 문자열이 있어도 된다
words = ["apple","banana","cherry","date"]
def solution(arr):
# {5:2, 6:1, 4:1}
result = {}
for i in arr:
length = len(i)
if length in result:
result[length] += 1
else:
result[length] = 1
return result
a = solution(words)
print(a) #{5: 1, 6: 2, 4: 1}
Day 17
어제 만든 데이터프레임 형식을 활용한 다양한 값도출 방법
df= pd.DataFrame(Data)
# shape 행과 열의 수를 돌려줌
print(df.shape)
# column 열
print(df.columns)
# values 데이터
print(df.values)
# 해당 열 뽑기
print(df.[['age','name']])
# 해당 열 뽑기 (+조건)
print(df[df['age']>30])
print(df[df['gender']=='f']) # 여성 sort
print(df[df['gender']=='f'][df['age']==40]) # 여성 & 40세
# 행뽑기
print(df.loc[0]) #첫번째 행
print(df.loc[0],'name') #첫번째 행, name 값
데이터 시각화하기
matplotlib 를 활용한 데이터 그래프화
import pandas as pd
#matplotlib 인스톨
import matplotlib.pyplot as plt
#pyplot 은 그래프화 도구모음
x = [1,2,3,4,5]
y = [20,25,30,35,40]
plt.plot(x,y)
plt.show()
1. 라이브러리란 : 라이브러리는 특정 기능을 수행하는 함수나 클래스들의 모음임. 이들을 사용함으로써 개발 시간을 단축하고, 오류를 줄일 수 있음.
2. 파이참에서 라이브러리 설치하기 : 파이참에서는 프로젝트 설정을 통해 쉽게 라이브러리를 추가할 수 있음 ( File > Settings > Project : [프로젝트이름] > Python Interpreter ) 로 이동하여 필요한 라이브러리를 검색하고 설치할 수 있음
3. 라이브러리 사용 : 라이브러리를 설치한 후에는 import 구문을 사용하여 코드 내에서 해당 라이브러리를 호출하고, 그 기능을 사용할 수 있음.
import pandas as pd
from faker import Faker
fake = Faker('ko_KR')
print(fake.name())
carData = {
'carName' : ['k5','k7','avante','k3','tesla'],
'owner' : [fake.name() for i in range(5)]
}
print(carData)
#{'carName': ['k5', 'k7', 'avante', 'k3', 'tesla'], 'owner': ['나정호', '최현지', '김지우', '김유진', '이경수']}
df = pd.DataFrame(carData)
df.to_csv('car.csv',index=False)
결과 화면
(Pandas 예시 4)
import pandas as pd
import random
from datetime import *
from faker import Faker
fake = Faker('ko_KR')
movieList = ['웡카','시민덕희','도그맨','너의 이름은','라라랜드','상견니','외계인']
snackList = ['일반팝콘','캬라멜팝콘','치즈팝콘','구운오징어','나초','프레즐','핫도그']
drinkList = ['콜라','제로콜라','스프라이트','환타','에이드','물']
cgvData = {
'customers' : [fake.name() for i in range (500)],
'movies' : [random.choice(movieList) for i in range (500)],
'snack': [random.choice(snackList) for i in range(500)],
'drink': [random.choice(drinkList) for i in range(500)]
}
cgv_df = pd.DataFrame(cgvData) #위 cgv 데이터를 데이터프레임화 시키기
now = datetime.now()
cgv_df.to_csv(f"cgv.csv",index=False) #제목에 {now}가 안되서 그냥 cgv.
def solution(phone_number):
newNumber = ""
for index,item in enumerate(phone_number):
if len(phone_number)-4 > index:
newNumber += "*"
else:
newNumber += item
return newNumber
a = solution("01012345678")
print(a) #*******5678
Day 15
프로그래밍에는 3대 에러가 있음
1. 컴파일 에러: 문법 오류 2. 런타임 에러: 실행중 오류 3. 컨텍스트 에러: 사람만 알 수 있는 오류 (테스터가 있는 경우)
예외 처리의 정의 (Exception)
Exception은 프로그램 실행 중에 발생하는 예기치 않은 상황이나 오류를 의미함. Exception Handling 은 이러한 예외 상황을 감지하고, 프로그램을 안전하게 종료하거나 문제를 해결하기 위해 정의된 방식으로 처리하는 기술임.
(try ~ except 파이썬 문법)
try
예외가 발생할 가능성이 있는 구문
except
예외가 발생하면 실행 되는 구문
else
예외가 실행되지 않으면 실행 되는 구문
finally
예외가 발생하던 발생하지 않던 무조건 실행되는 구문
(에러가 발생 할 수 있는 경우!)
ValueError
함수가 올바른 유형의 값을 받았지만, 그 값이 올바르지 않은 경우 발생
IndexError
리스트,튜플,문자열 등의 시퀀스에서 인덱스가 범위를 벗어난 경우 발생
KeyError
딕셔너리에서 존재하지 않는 키를 검색할 때 발생
AttributeError
객체에 존재하지 않는 속성이나 메서드를 접근하려고 할 때 발생
ZeroDivisionError
숫자를 0으로 나누려고 할 때 발생
TypeError
연산이나 함수가 적절하지 않은 유형의 객체에 적용될 때 발생
(try ~ except 예시)
try: #try는 에러가 날 것 같은 구문을 적는 곳!
num = int(input("숫자 입력:"))
result = 10 / num
print(f'결과는 {result}')
except Exception:
print('에러가 있습니다.')
try: #try는 에러가 날 것 같은 구문을 적는 곳!
num = int(input("숫자 입력:"))
result = 10 / num
print(f'결과는 {result}')
except ValueError:
print('제발 숫자를 입력하세요.')
except ZeroDivisionError:
print("0으로 못나눕니다.")
else:
print('에러없습니다')
finally:
print('상관없으니 보여주라')
소프트웨어 Hierarchy
컴포넌트 -> 모듈 -> 패키지 -> 라이브러리 -> 프레임워크 -> 어플리케이션
컴포넌트 : 재사용 가능한 독립적인 단위 모듈: 하나 이상의 컴포넌트를 포함하며, 상호 관련된 코드 그룹 패키지 : 하나 이상의 모듈을 포함하며, 기능 단위로 그룹화 라이브러리 : 다른 프로그램이나 프로젝트에 호출 되는 단위 ex) Pandas, Numpy 프레임워크 : 특정 개발 작업을 위한 기본 구조 제공 ex) Flask
(import sheet)
#첫번째 예시
import my_math as mm
result = mm.add(10,10)
print(result) #20
#두번째 예시
from my_math import add # add function만 가져옴
result2= add(10,20)
print(result2) #30
#세번째 예시
from my_math import * # *는 다~가져오겠음
result3= add(1,3)
print(result3) #4
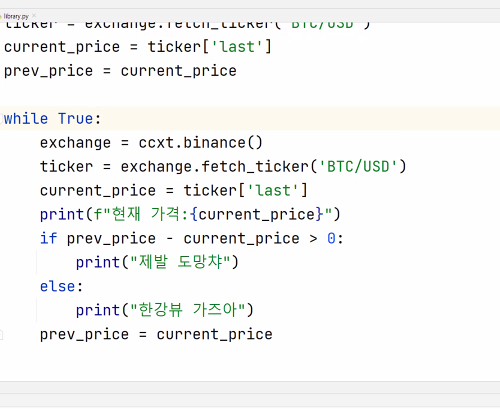
(라이브러리에서 yfinance를 인스톨) (설정 > 프로젝트 인터프리터 > 패키지 검색 & 인스톨)
import yfinance
apple = yfinance.Ticker("AAPL")
current_price = apple.info['currentPrice']
print(f"애플주식의 현재 가격: {current_price}")
# 애플주식의 현재 가격: 193.89
ms = yfinance.Ticker("MS")
current_price = ms.info['currentPrice']
print(f"마이크로소프트의 현재 가격: {current_price}")
# 애플주식의 현재 가격: 193.89
#마이크로소프트의 현재 가격: 85.73
상속과 추상 상속 (inheritance): 객체지향 프로그래밍에서 매우 중요한 개념. 상속을 통해 한 클래스 (자식)가 다른 클래스 (부모)의 속성과 메서드를 그대로 이어받을 수 있음. 이는 코드의 재사용성을 높이고, 중복을 줄여 프로그램의 구조를 더욱 효율적으로 만듬.
(상속의 기본 문법:)
class ParentClass:
#부모 클래스의 메서드와 속성 정의
pass
class ChildClass(ParentClass):
#자식 클래스에서 추가된 메서드와 속성 정의
pass
오버라이딩 (Overriding) 오버라이딩은 자식 클래스가 부모 클래스로부터 상속받은 메서드를 자신의 필요에 맞게 재정의하는 것을 의미함. 이를 통해 상속받은 기능을 유지하면서도, 특정 부분을 자식 클래스에 맞게 커스터마이징 할 수 있음.
오버라이딩의 특징: (재정의): 부모 클래스의 메서드와 동일한 이름, 매개변수로 자식 클래스에서 메서드를 재정의 (확장): 부모 클래스의 기능을 유지하면서 추가적인 기능을 더할 수 있음 (다형성): 같은 메서드 이름으로 다양한 기능을 구현할 수 있어, 다형성을 실현하는데 중요한 역할을 함
(상속과 오버라이딩 예시)
class Monster:
def __init__(self,hp,name,damage):
self.hp = hp
self.name = name
self.damage = damage
def attack(self,character):
character.hp -= self.damage
class Slime(Monster):
def __init__(self,hp,name,damage,poison):
super().__init__(hp,name) # 위 부모의 init(생성자)을 넣기
self.poison = poison # 자기의 생성자
def attack(self, character):
character.hp -= self.damage * 2 # overriding 예시
def sprayPoison(self,character):
character.hp -= self.damage + self.poison
#kim = character()
a = Slime(50,'귀여운슬라임',30,5)
a.attack(kim)
a.sprayPoison(kim)
(abstract class 예시)
from abc import ABC, abstractmethod
class Shape(ABC):
@abstractmethod
def get_area(self):
pass
@abstractmethod
def get_round(self):
pass
class Circle(Shape):
def __init__(self,r):
self.radius = r
def get_area(self):
return 3.14*self.radius**2
def get_round(self):
return 3.14*self.radius*2
class Triangle(Shape):
def __init__(self,b,h):
self.base = b
self.height = h
def get_area(self):
return self.base * self.height * 0.5
def get_round(self):
return self.base * 3
class Square(Shape):
def __init__(self,s):
self.side = s
def get_area(self):
return self.side * self.side
def get_round(self):
return self.side * 4
a = Triangle(5,5)
print(a.get_area()) #12.5
print(a.get_round()) #15
b = Square(8)
print(b.get_area()) #64
print(b.get_round()) #32
객체지향프로그래밍 (OOP) 요소: 캡슐화 (encapsulation) - 데이터보호, 상속 (inheritance) - 코드 간략화, 다형성 (polymorphism) - 코드 유지보수 용이
원칙: SOLID 원칙의 소개 및 설명 (class 잘 만드는 방법) S: 단일 책임 원칙 O: 개방/폐쇄 원칙 L: 리스코프 교환 원칙 I: 인터페이스 원칙 D: 의존성 역전 원칙
def reverseStr(my_string):
strList = list(my_string) # my_string 리스트화 하면 [b,r,e,a,d]
strList.reverse() # [d,a,e,r,b]
word = ""
for i in strList:
word += i
return word
a = reverseStr("bread")
print(a) # daerb
todo_list = ["problemsolving","practiceguitar","swim","studygraph"]
finished = [True, False, True, False]
def haveto_List(todoList,finishedList):
return [todoList[index] for index,item in enumerate(finishedList) if not item]
print(haveto_List(todo_list,finished))
Day 13
객체의 개념
객체란? 객체는 속성(변수)과 메서드(함수)를 하나의 단위로 묶은 것임. 예를 들어, 자동차를 객체로 생각하면 이 자동차 객체에는 여러 속성 (색상, 브랜드, 연식 등)과 메서드 (운전하기, 정지하기, 경적 울리기 등)가 있음.
속성: 속성은 객체의 특징을 나타냄. 예를 들어, 자동차의 색상 (빨강,파랑), 브랜드 (BMW, 테슬라), 연식 (2020년,2021년) 등이 속성에 해당함.
메서드: 메서드는 객체가 수행할 수 있는 행동임. 예를 들어, "DRIVING", "HONKING", "INTRODUCING" 등의 기능을 수행하는 것이 메서드에 해당함.
객체의 생성자 (CONSTRUCTOR)
생성자는 객체가 생성될 때 자동으로 호출되는 특별한 메서드로, 파이썬에서는 __init__ 메서드를 사용하여 생성자를 정의함
(Class 활용 예시1)
class Car:
def __init__(self,b,n,c): #변수/구조체 [명사/상태]
self.brand = b
self.name = n
self.color = c
def introduce(self):
print(f"차의 이름은 {self.name} 브랜드는 {self.brand} 차 색깔은 {self.color}입니다 ")
def horning(self):
print("빵빵 경적 울립니다~")
def driving(self):
print("부릉부릉 앞으로 갑니다~")
a = Car('Hyundai','k5','black')
b = Car('Kia','모닝','purple')
a.driving() #부릉부릉 앞으로 갑니다~
a.introduce() #차의 이름은 k5 브랜드는 Hyundai 차 색깔은 black입니다
b.horning() #빵빵 경적 울립니다~
b.introduce() #차의 이름은 모닝 브랜드는 Kia 차 색깔은 purple입니다
가변 매개변수 (*args) 설명: args는 여러 개의 위치 인수를 받을 수 있게 해주며, 함수에서 몇 개의 인수를 받을 지 미리 정할 수 없을 때 유용함. 예시: 아래 toppings는 여러개의 인수를 받을 수 있음
(출생년도에 대한 띠 zodiac 알려주기 예시)
def zodiac(*years):
sign = ['닭띠','개띠','돼지띠','쥐띠','소띠','호랑이띠','토끼띠','용띠','뱀띠','말띠','양띠','원숭이띠']
# newList = []
# for i in years:
# newList.append(sign[i - 1993])
# return newList
return [sign[i-1993] for i in years] # 위 커멘드들의 요약버전
a = zodiac(1993,1994,1999,2002)
print(a) #['닭띠', '개띠', '토끼띠', '말띠']
람다함수 : 간결하고 익명의 한 줄 함수로, 작은 연산이나 변환에 적합
내용 요약 정의: 람다 함수는 이름이 없는 익명 함수로, 간단한 함수를 한 줄로 작성할 수 있게 해주며, 주로 작은 연산이나 데이터 변환에 사용됨. 차이점: 일반 함수는 def 키워드를 사용하여 정의되고 이름을 가지며, 복잡한 로직을 포함할 수 있음. 반면, 람다 함수는 간단한 표현식을 위해 사용되며, lambda 키워드로 정의되고 이름을 가지지 않음.
plus = lambda a,b: a+b
result = plus (5,7)
print(result) #12
minus = lambda a,b: a-b
result2 = minus(5,2)
print(result2) #3
mult = lambda a,b,:a*b
result3 = mult(4,5)
print(result3) #20
콜백함수 다른 함수에 전달되어 특정 이벤트나 조건 후에 실행되는 함수 g(f(x))
정의: 1. 콜백 함수는 일반적인 함수처럼 정의되지만, 다른 함수에 인자로 전달됨 2. 콜백 함수를 정의하고, 다른 함수에 인자로 전달하여 호출함 3. 파이썬에서는 모든 함수가 일급 객체이므로, 함수를 변수에 할당하거나 다른 함수의 인자로 전달 할 수 있음
“입주 물량 말라버린 서울, 그 종착점은 어디인가!” PF대출, 빌라포비아, 중국 경제위기… 2024년에 다가올 위기와 기회들 “먼저 시장을 이해하는 자가 승자가 된다!”
“2024년은 기회를 노리는 이들이 새로운 준비를 해야 하는 해다. 어떤 투자건 시장의 흐름을 먼저 알아채는 자가 승자가 된다.” _프롤로그 중에서
2년 연속 완벽 적중한 김경민 교수의 ‘집값 시나리오’
매년 빅데이터 분석을 근거로 서울시 집값 예상치와 당해의 투자 이슈를 짚어주는 [부동산 트렌드] 시리즈가 2024년 부동산 시장을 전격 해부한다. 2023년 현재, 뉴스마다 주택 가격의 반등세를 확신하는 의견과 추가 하락을 경고하는 주장이 뒤엉켜 있다. 투자자도 실수요자도 상반된 시각에 혼란스러워 하며 정확한 데이터와 균형 있는 의견을 제시해줄 전문가를 절실히 찾고 있다. 지난 저서들을 통해 서울시 집값이 2018년 4분기 수준으로 회귀하며 25% 이상 하락할 것이라 말한 김경민 교수는 가격 변곡점뿐만 아니라 구체적인 하락률까지 적중시켜 모두를 놀라게 했다. 심지어 도곡렉슬, 올림픽훼밀리타운, 남산타운 등 서울 주요 아파트 단지별 변동 폭까지 정확히 맞혔다. [부동산 트렌드 2024]는 더욱 정밀해진 분석으로 ‘2024년 아파트 가격’에 대한 시나리오를 제시한다. 투자자들은 그의 전망을 통해 자신의 위험 성향과 주택 보유 여부에 맞는 부동산 전략을 세울 수 있을 것이다.
<부동산트렌드 2024> 저자 소개
서울대학교 지리학 학사, UC 버클리 정보시스템 석사를 거쳐 하버드대학교에서 도시계획·부동산 연구로 박사 학위를 받았다. 현재 서울대학교 환경대학원 도시계획 전공 교수로 재직 중이다. 보스턴 소재의 상업용 부동산 리서치회사 PPR에서 오피스 가격 예측 모형을 구축하고 글로벌 부동산을 연구했다. 주요 연구 분야는 빅데이터 기반 부동산 시장 분석, 글로벌 오피스 비교, 공공민간협동개발 등이다.
지은 책으로는 빅데이터로 부동산 시장을 해부하고 미래 가격을 정확히 예측한 ≪부동산 트렌드 2022≫, ≪2020 부동산 메가트렌드≫, 도시개발의 방향성을 제시한 ≪도시개발, 길을 잃다≫, 익선동의 가치를 재조명한 ≪리씽킹 서울≫, 북촌을 개발한 기농 정세권 선생을 다룬 ≪건축왕, 경성을 만들다≫ 등이 있다.
대한민국 최고의 부동산 전문가로서 부동산 입문자와 투자자의 든든한 안내자 역할을 해온 김경민 교수는 하버드 박사를 의미하는 ‘하박’이라는 별명으로 불리며 각종 미디어에서 종횡무진 활동 중이다. 출연한 프로그램으로는 EBS의 〈비즈니스리뷰〉, 〈클래스e〉, MBC의 〈100분토론〉, 부동산 파일럿 〈돈벌래〉, tvN 〈미래수업〉, 유튜브 채널 ‘삼프로TV’ 등이 있다. 또한 유튜브 채널 ‘김경민의 노트’와 부동산 오픈데이터 플랫폼 ‘부트캠프’를 통해 누구나 쉽게 시장 트렌드를 파악할 수 있도록 부동산 정보 공유를 위해 힘쓰고 있다.
<부동산트렌드 2024> 주요 내용 요약
이 책의 부제목이 "서울 아파트 상승의 전조"인 만큼, 책에서는 향후 서울 아파트 가격 흐름의 상방압력과 하방압력에 대해 설명한다. 큰 틀에서 설명하면, 현재 부동산 시장에서 주의 깊게 보아야 하는 부분은 기준금리보다는 '주택담보대출금리'의 흐름이며, 이와 연관되는 국고채 10년물 금리를 지켜봐야한다고 한다. 중장기적으로는 빌라포비아의 여파, PF대출 연장의 여파, 그리고 최악의 수준으로 예상되는 2025-2026년 이후의 서울시 아파트 입주물량이 시장에 영향을 미칠 것으로 예상하고 있다.
(2024 트렌드 1) 고가 아파트 시장의 분화 강남 인근 중에서도, 고가 아파트 시장인 제 1 권역 (강남-서초)에는 제 2 권역 (송파-강동)에서의 가격 하락이 전달되지 않았으며, 이는 고가 아파트 시장이 분화하고 있음을 뜻한다.
(2024 트렌드 2) 거래량 회복의 3가지 원인 책에서는 2023년 거래량이 증가한 원인 3가지를 제시하고 있다. 첫째: '특례보금자리론'의 정책 효과 (9억원 이하 아파트 거래량이 급격하게 증가) 둘째: 주택담보대출(신규) 금리가 2022년 10월부터 급격하게 낮아지면서 주택 수요 자극 셋째: 갈아타기 수요의 등장 (전세가율이 40% 수준인 가운데 9억원 이상 및 15억원 이상의 아파트도 거래량이 빠르게 증가)
상품
기존
개편
우대형 안심전환대출 (일반형)
보금자리론
적격대출
특례보금자리론
주택 가격
6억 원
6억 원
9억 원
9억 원
대출 한도
3.6억 원
3.6억 원
5억 원
5억 원
소득 한도
1억 원
7,000만 원
없음
없음
금리
3.8~4.0%
4.25~4.55%
4.55~6.91%
단일금리 산정체계 (+우대금리 적용)
(특례보금자리론 시행 방향, 기존 vs 개편)
(2024 트렌드 3) 입주량의 급감 보통 인허가로부터 3-4년 뒤 아파트가 공급되는데, 2022-2023년 서울 아파트 인허가 물량이 역대 최저 수준이다. 이는 단기적으로 2025-2026년 서울 아파트 전세가격을 상승을 야기할 수 있을 것으로 보인다.
(2024 트렌드 4) 빌라와 아파트 시장 단기, 중장기 전망
단기 (2024년)
중기 (2025년 이후)
빌라 시장
- 빌라포비아의 여진 - 아파트로의 이주 수요 발생 - 아파트 전세가격 상승 가능성
- 빌라 공급 급감 - 빌라 전세가격 상승 가능성 - 아파트로의 이주 수요 발생 - 아파트 전세가격 상승 가능성
아파트 시장
- 높은 토지 가격이 개발 위축 - 아파트 인허가 급감
- 아파트 입주량 급감 - 아파트 전세가격 상승 가능성
(2024 트렌드 5) 서울시 8개 대장 단지 분석을 통해 본 5가지 인사이트 [1] 소형 평형대의 뛰어난 안정성: 일반적인 시장 상황에서 25평형은 33평형에 비해 매우 안정적인 흐름을 보여준다 [2] 소형 평형대의 높은 상승률: 왕십리 뉴타운을 제외한 7개 대장 단지에서 25평의 상승률이 33평형보다 높게 나타난다 [3] 지역별 가격 차이의 확대: 강남-서초 권역과 송파-강동 권역의 분화가 일어나고 있으며, 미시적 공간 차원에서도 가격 차이가 확대될 가능성이 높아진다 [4] 업무지구 접근성의 중요성: 업무지구가 거대하게 자리잡은 강남을 제외한 다른 지역은 2호선 내부와 외부를 기준으로 아파트 시장이 분화될 가능성이 높다 [5] 임대 아파트 존재 여부와 가격: 대단지, 대중교통망, 업무지구로의 접근성과 같은 강력한 어메니티가 존재하는 단지는 임대 아파트 세대 수가 아무리 많더라도 이를 넘어서는 강한 상승 동력이 존재한다
<부동산트렌드 2024> 서민 주거복지를 위한 정책 제언
<부동산트렌드 2024>에서 저자는 5가지 정책 제언을 제시하고 있다.
1. 정부 주도의 거대한 리츠 (REITs)를 만들어야 한다*
2. 서울 내부와 인근의 토지를 대규모로 확보하는 랜드 뱅킹 (Land Banking) 전략을 빠르게 도입해야 한다
3. 저렴한 토지 기반 아파트 대량 공급 정책이 필요하다
4. 전세의 반전세화를 제도화해야 한다
5. PPD (Private Public Development, 민간 공공 협동개발) 형태의 개발 방식 도입이 필요하다
*우리나라 공공기관이 보유한 공공임대주택 물량은 2023년 기준 전체 주택 수 대비 8.9% 비중으로, OECD 상위 국가에 비하면 낮은 수준이라고 한다. 이 통계에 전세임대주택을 비롯한 10년 이하 단기임대주택 등이 포함된 것을 감안한다면, 실제 장기공공임대주택은 5% 내외에 불과할 것이다. 우리가 많이 참조하는 도시국가 싱가포르는 토지임대부 분양 주택과 공공임대주택 등 공공이 제공하는 주택이 80%를 초과한다. 그 결과 최근 5년간 서울 부동산은 급등한 데 반해 싱가포르는 안정적인 주택 가격을 유지하고 있다.
#방법1
[i for i in range (1,21) if i % 2 ==0]
#방법2
[i for i in range (2,21,2)]
# REVIEW 2) 주어진 리스트 [1,2,3,4,5,6,7,8,9,10]에서 5보다 큰 숫자만을 포함하는 새로운 리스트를 리스트 컴프리헨션을 사용해 만들기
numList = [1,2,3,4,5,6,7,8,9,10]
overFiveList = [i for i in numList if i > 5]
print(overFiveList) #[6,7,8,9,10]
# REVIEW 3) 문자열 리스트 ['apple','banana','cherry','date']에서 각 단어의 첫 글자만을 추출하여 새로운 리스트 만들기 # 예상 답안 ['a','b','c','d']
fruits = ['apple','banana','cherry','date']
firstLetterList = [i[0] for i in fruits]
print (firstLetterList) # ['a','b','c','d']
# REVIEW 4) 위의 FRUITS를 대문자화 하기
fruitsUpper= [i.upper() for i in fruits]
print(fruitsUpper) # ['APPLE','BANANA','CHERRY','DATE']
Day 10 딕셔너리 컴프리헨션 (Dictionary Comprehension) 딕셔너리 컴프리헨션은 Key 값과 Value 쌍을 생성하여 Dictionary를 만드는데 사용됨. 구조: {키 : 값 for 변수 in 리스트 or 문자열}
zip 함수의 기본 사용법 #1. zip 함수를 이해하기 쉬운 비유로 설명하자면, 'zipper' 처럼 서로 다른 두 줄의 요소들을 하나씩 짝지어 올리는 것임 #2. zip 함수는 두 개 이상의 리스트를 받아서, 첫 번재 리스트의 첫 번째 요소와 두 번째 리스트의 첫 번째 요소를 묶고, 다음으로 두 번째 요소들을 묶는 식으로 진행
# REVIEW 1 1부터 100까지의 사이 출력한 뒤 정수 N의 배수만 출력하도록 만들기
num = int(input("정수 입력하기: "))
for x in range (101):
if x % num == 0:
print(x)
# REVIEW 2 정수를 받고, 구구단 (x1 ~ x9) 출력하기
num1= int(input("정수 입력:"))
for i in range (1,10):
print(f"{num1} * {i} = {num1 * i}") # 5*1=5 5*2=10
DAY 9 BREAK: FOR, WHILE 에 반복을 끊는 역할 CONTINUE: JUMP 같은 역할
(break 예시)
for i in range (100):
if i==50:
break
else:
print(i) # 0 1 2 3... 49
(continue 예시)
for i in range (100):
if i==50:
continue
else:
print(i) # 0 1 2 3 ... 49 51 .. 99
Day 9 While 문 : 파이썬에서 while 문은 조건이 True인 동안 반복해서 코드 블록을 실행하는 데 사용 됨. while 루프는 주어진 조건이 False가 될 때까지 계속 실행되며, 조건이 처음부터 False이면 루프 내부의 코드는 한 번도 실행되지 않음.
While 은 유저가 끝을 결정 짓는 상황, For 는 프로그래머가 끝을 결정 짓는 상황으로 이해할 수 있음!
(while문 기본 구조 1)
a=1
while a < 10:
print ('아메리카노')
a=a+1 # a += 1
#결과: 아메리카노 9번 써짐
(while문 기본 구조 2)
while True:
print("너가 숫자 1을 넣어야 탈출 가능")
num=int(input("숫자 입력:"))
if num == 1 :
break
(while문의 응용 - 커피 프로그램 개발-)
coffeeList=[]
while True:
print("-메가커피 프로그램-")
print("1. 커피 등록하기")
print("2. 커피 메뉴보기")
print("3. 시스템 종료")
codeNumber = int(input("번호 입력: "))
if codeNumber==1:
print("커피 등록 시스템")
coffeeName=input("커피 이름 입력")
coffeeList.append(coffeeName)
print("등록 완료!")
elif codeNumber ==2:
if len(coffeeList) == 0:
print("커피 메뉴가 없어요ㅠ.ㅠ")
else: print(coffeeList)
elif codeNumber ==3:
print("이용해 주셔서 감사합니다.")
break
else:
print("숫자를 다시 입력하세요")
Day 9 For 문 컴프리헨젼 파이썬에서의 리스트 컴프리헨션 (List Comprehension)은 for 문을 사용하여 리스트를 생성하는 간결하고 효율적인 방법임. 기본적인 for 문 대신에 리스트 컴프리헨션을 사용하면 코드를 더 짧고 읽기 쉽게 만들 수 있음
(기존 FOR문)
a = []
for i in range (1001):
a.append(i)
print(a)
(FOR_COMPREHENSION 예시)
a = [i for i in range (1001)]
print(a) #[1, 2, 3.... , 1000]
b = [i for i in range (101)]
print(b) #[1,2,3...,100]
c = [i for i in range (1,501)]
print(c) #[1,2,3...,500]
d = [i for i in "megastudy"]
print(d) # ['m','e','g','a',..'y']
e = [i*2 for i in range (1,101)]
print(d) # [2,4,6,8...200]
#1. 1~10을 각각 제곱한 수의 리스트
f = [i**2 for in range (1,11)]
print(f)
#[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
#2. 1~10에 각각 5를 더한 수의 리스트
g= [i+5 for i in range (1,11)]
print(g)
#[6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
조건부 컴프리헨션 (Conditional Comprehension) 컴프리헨션 내에 if-else 조건문을 사용하여 특정 조건에 따라 다른 값들을 생성 구조: [값1 if 조건 else 값2 for 변수 in 반복가능객체]
(예시 1) IF가 뒤에 있을 때에는, FILTER 역할 수행!)
fruits =['apple','strawberry','mango','orange','melon']
for i in fruits :
print(i) # apple strawberry mango ...
#예시) alphabet a 가 있는 애들만 찾기
a = [i for i in fruits if i.count('a')>0]
print(a) #['apple', 'strawberry', 'mango', 'orange']
#예시) alphabet r 이 하나만 있는 애들만 찾기
b = [i for i in fruits if i.count('r')==1]
print(b) #['orange']
#글자 개수가 6글자 이상만 찾기
c = [i for i in fruits if len(i) >= 6]
print(c) #['strawberry', 'orange']
(예시 2) IF - ELSE 가 있을때는 MAP 변환/치환 역할 수행!
d = [':>' if i%2 ==0 else i for i in range (1,101)]
print(d) #[1, ':>', 3, ':>', 5, ':>', 7, ':>', 9, ':>',...:>(100)]
(활용 1) 유저에게 n을 입력 받고, 1~100까지의 리스트 출력을 하는데 n 의 배수만 @를 표현해주고 나머지는 숫자로 표현
n=int(input("정수 입력: "))
e = ['@' if i%n==0 else i for i in range (1,101)]
print (e)
# 5 넣으면 [1, 2, 3, 4, '@', 6, 7, 8, 9, '@' ... '@]
(활용 2) fruits = ['apple','strawberry','mango','orange','melon'] fruits 에서 5글자 이하이면 대문자로 바꿔서 출력하고 아니면 #로 출력하는 리스트 만들기
f = [i.upper() if len(i)<=5 else '#' for i in fruits]
print (f) #['APPLE', '#', 'MANGO', '#', 'MELON']
중첩 루프 컴프리헨션 (Nested Loop Comprehension) 컴프리헨션 내에 두 개 이상의 반복문을 중첩하여 사용 가능. 이는 여러 개의 리스트나 다른 반복 가능한 객체들 간의 조합을 생성하는 데 유용 구조: [값 for 변수1 in 반복가능객체1 for 변수2 in 반복가능객체2]
h=[i*j for i in range (1,4) for j in range (1,4)]
#i:1일때 j: 1,2,3
#i=2일때 j: 1,2,3
#i=3일때 j: 1,2,3
print(h)
#결과: [1, 2, 3, 2, 4, 6, 3, 6, 9]
g=[i+j for i in ["apple","banana"] for j in ["pie","tanghuru"]]
print(g)
# 결과: ['applepie', 'appletanghuru', 'bananapie', 'bananatanghuru']
# (REVIEW 2) # # 테마파크 입장권과 놀이기구 이용 패키지 # # 입장권 종류 1~3과 나이를 입력 받고, 패키치에 따라 가격 계산 # # 1. 일반 입장권 50000 # # 2. 프리미엄 입장권 75000 # # 3. VIP 입장권 100000 # # 나이에 따른 할인율 # # 12세 미만 50% 할인 # # 65세 이상 30% 할인
park = {
1: {
'name': '일반 입장권',
'price': 50000
},
2: {
'name': '프리미엄 입장권',
'price':75000
},
3: {
'name':'VIP 입장권',
'price':100000
}
}
name_choice = int(input("파크 고르세요! (1 일반 2 프리미엄 3 VIP) : "))
age = int(input("나이 :"))
if age <= 12:
print(f"총 이용 요금은 {park[name_choice]['price']*.5} 입니다")
elif age >= 65:
print(f"총 이용 요금은 {park[name_choice]['price']*.3} 입니다")
else:
print(f"총 이용 요금은 {park[name_choice]['price'] * 1} 입니다")
# (REVIEW 3) 0~10,000까지의 랜덤을 숫자를 담고 있는 6개의 정수를 담고 있는 리스트 출력
import random
num= []
for x in range (6): #6개 추출
number=random.randint(0,10001) #0~10000까지를 랜덤 추출
num.append(number)
num.sort() #오름차순 정렬
print(num)
본 수업
# (for 기본) for x in "단어" 입력시 알파벳별 나열된다
for x in "icecream":
print(x) # i c e c r e a m
# (for 활용) 텍스트를 입력하고, 소문자를 대문자로, 대문자를 소문자로 만들기
# 유저에게 InpUT 받고 -> iNPut 출력
user = input("단어 입력: ")
word = ''
for x in user:
if x.isupper():
word = word + x.lower() # ''+'i' => i
else:
word = word + x.upper() # i + N => iN
print(word)
# (for 활용) 단어 내에 'a' 'e' 가 포함되어 있으면, 없애기
user = input ("단어 입력: ")
output = ''
#apple
for x in user:
if x == 'a' or x == 'e':
output = output
else:
output = output + x
print(output)
#
# (for 활용) 단어 내에 'a' 'e' 'i' 'o' 'u' 가 포함되어 있으면, 없애기 ( pass )
user = input ("단어 입력: ")
output = ''
#apple
for x in user:
if x in 'aeiou':
pass
else:
output += x
print(output) #ppl
# (for 활용) 리스트 내에 있는 단어 수를 가져다가 리스트로 만들기
list=[]
for x in ['사과', '바나나','파인애플']:
print(len(x)) # 2 3 4
list.append(len(x))
print(list) # [2,3,4]
# (for 활용) 짝수 리스트, 홀수 리스트 만들기
even=[]
odd=[]
evenSum=0
for x in [1,2,3,4,5,6,7,8,9,10]:
if x % 2 == 0:
even.append(x)
else: odd.append(x)
print(even) # [2,4,6,8,10]
print(odd) # [1,3,5,7,9]
# (for 활용) 0 ~ 10,000 까지의 범위에서 100개의 정수 리스트를 받고, 리스트에서 홀수면 'odd' 짝수면 'even'으로 값 변경하기
import random
List=[]
for x in range (100):
List.append(random.randint(0,10001))
print(List)
List.sort()
print(List)
evenoddList= []
for x in List:
if x % 2 ==1:
evenoddList.append('odd')
else:
evenoddList.append('even')
print(List) # [30, 450, 523, 534, 627, 735, 971...
print(evenoddList) # ['even', 'even', 'odd', 'even', 'odd'..
for 변수 in (리스트, 문자열 ... ) [ 반복 가능한 객체 ]
for 변수 in enumerate ( ) enumerate( ) 함수는 리스트, 문자열 등을 순회하면서, 각 요소의 인덱스와 값을 동시에 얻을 수 있게 해줌
(enumerate 함수 예시)
device=['아이폰','갤럭시','맥북']
for x,y in enumerate(device): #enumerate는 요소와 순서를 둘다 알려줌
print(f"{x}.{y}") #0.아이폰 #1. 갤럭시 #2. 맥북
이 연구에서는 헬싱키 중심도시를 배경으로 대도심권에 위치한 신규 시장가격*의 주택 공급 (market-rate housing supply)이 도시 전체에 주는 영향을 분석한다.
(연구 데이터) 지리적 코딩이 들어간 (geo-coded register data) 2009-2019년 10년간 핀란드 전역의 주거민 데이터를 활용해 나이, 성별, 소득수준, 교육수준, 자녀수 등을 파악하고, moving chain을 구성하는데 가장 중요한 년도별 주거민의 주소지 또한 포함된다.
(분석기법) 기준 시점 t의 거주지와 이전년도 (t-1) 주거지를 파악하는 방법으로 6번에 걸쳐 주거이동 패턴을 그린다.
(연구 결과) Harjunen과 Saarimaa는 신규 시장가격의 주택이 보통 상대적으로 높은 소득 수준의 가구로부터 소비되지만, moving chain 분석 결과에 따르면, 결국 중위-하위 소득의 가구들에게도 긍정적 영향을 미친다고 주장한다. 이는 기존 Been et al. (2019)가 주장한 '신규 시장가격의 주택 공급이 고소득층에게만 혜택을 가져다준다'는 주장을 반박하며, Mast (2021) 과 함께 신규 시장가격의 주택 공급의 이점에 힘을 보태고 있다.
Been, V., Ellen, I.G., O’Regan, K., 2019. Supply skepticism: housing supply and affordabil- ity. Hous. Policy Debate 29 (1), 25–40.
Mast, E., 2021. JUE insight: the effect of new market-rate housing construction on the low- income housing market. J. Urban Econ., 103383 doi:10.1016/j.jue.2021.103383.
Glaeser, E., Gyourko, J., 2018. The economic implications of housing supply. J. Econ. Perspect. 32 (1), 3–30.
Glaeser, E.L., Ward, B.A., 2009. The causes and consequences of land use regulation: evi- dence from Greater Boston. J. Urban Econ. 65 (3), 265–278.
num=int(input("숫자 입력: "))
print(num % 2)
if num % 2 == 1:
print ("홀수 입니다")
else: print("짝수 입니다")
#2 문자 한개를 입력하고, 알파벳이면 '알파벳입니다', 아니면 '알파벳이 아닙니다' 알려주는 프로그램 if문 & <name.isalpha( ) 활용>
text=(input("문자 입력: "))
print(text.isalpha())
if text.isalpha() == True: #== True 부분 생략 가능!
print ("알파벳 입니다")
else:
print ("알파벳이 아니에요")
#3 비밀번호 설정 프로그램 - 최소 10자 이상, - 영문과 숫자의 조합 필요, - 특수문자 하나 이상 포함!
pw=(input("비밀번호 입력: "))
if len(pw) < 10:
print ("최소 10글자 설정해주세요")
elif pw.isalnum() == True: # pw.isalnum() 은 알파벳/ 혹은 숫자인지 알려준다
print ("영어와 숫자를 꼭 포함해 주세요")
elif ('!' in pw or '@' in pw or '#' in pw or '$' in pw) == False:
print("특수문자를 포함해주세요")
else:
print ("비밀번호 설정 완료!")
#4 버스 요금 계산기 - 사용자로부터 버스 노선의 종류를 나타내는 정수와 승객의 나이를 입력받고, 노선별 요금 알려주기 - 노선별 요금: 1. 시내버스 (1200) 2. 광역버스 (2000) 3. 마을버스 (1000) - 연령별 할인율: 1. 7세 이하 어린이 (무료) 2. 8-19세 청소년 (30%) 3. 65세이상 노인 (무료)
bus={
1: {
'name': '시내버스',
'price': 1200,
},
2: {
'name': '광역버스',
'price': 2000,
},
3: {
'name': '마을버스',
'price': 1000,
},
}
bus_choice=int(input(f"버스를 선택하세요!: "))
age = int(input("나이를 입력하세요: "))
if age <= 7 or 65 <= age:
print ("무료 입니다!")
elif 8 <= age and age <=19:
print (f"{bus[bus_choice]['name']} 노선 요금은 {bus[bus_choice]['price']*0.7} 입니다")
else:
print(f"{bus[bus_choice]['name']} 노선 요금은 {bus[bus_choice]['price']} 입니다")
Random
파이썬에서 random 모듈은 난수를 생성하는 데 사용되며, 다양한 종류의 난수 생성 함수를 제공함. 이 모듈은 게임, 시뮬레이션, 테스팅, 보안 및 기타 많은 분야에서 활용 됨. 다음과 같은 주요 함수들이 포함 됨:
1. randint(a,b): a와 b 사이의 랜덤한 정수를 반환 2. random(): 0과 1 사이의 랜덤한 실수를 반환 3. choice(seq): 주어진 시퀀스 (리스트, 튜플 등)에서 랜덤한 요소를 반환 4. shuffle(x [,random]): 시퀀스 요소들을 무작위로 섞음
#random test
import random
print(random.randint(0,100)) #randint는 랜덤하게 정수 뽑기임(0부터 100까지)
print(random.random()) #0~1 사이의 실수 뽑기임
fruits = ['사과','망고','바나나','멜론']
print(random.choice(fruits)) #fruits에서 랜덤 뽑기
random.shuffle(fruits) #리스트를 넣고 shuffle하기
print(fruits)
반복문 For 문
반복문은 프로그램에서 같은 코드 도는 일련의 코드를 반복 실행하는 구조. 반복문을 사용하면, 동일한 작업을 여러번 수행하도록 컴퓨터에 지시할 수 있음
for 변수 in range (n) Range()함수 1. 한 매개변수를 가질 때 (range(stop#)) - 0부터 stop-1 까지의 숫자를 생성 - 예) range (5)는 0,1,2,3,4를 생성 2. 두 매개변수를 가질 때 (range(start,stop)) - start부터 stop-1까지의 숫자를 생성 - 예) range (2,5)는 2,3,4를 생성 3. 세 매개변수를 가질 때 (range(start,stop,step)) - start부터 시작해서 stop-1까지, step만큼의 간격으로 숫자를 생성 - 예) range (2,10,2)는 2,4,6,8을 생성
(활용예시)
# #유저에게 n번째까지의 정수를 받고, m 의 정수를 받으면
# # 0~n 까지의 m 의 공배수의 총합을 나타내는 프로그램
num=int(input("n번째까지의 정수 입력: "))
mul=int(input("m의 공배수: "))
sum=0
for x in range (num+1):
if x % mul ==0:
sum += x
print(f"총합: {sum}")
#for 함수 시작지점 다르게
for x in range (2,10): #0부터 말고, 2부터! 9까지!
print(x)
(응용예시)
#0~10,000까지의 랜덤을 숫자를 담고 있는 6개의 정수를 담고 있는 리스트 출력
import random
print(random.randint(0,10000))
numbers= []
for x in range (0,10):
number=random.randint(1,10001)
numbers.append(number)
print(numbers)
# #2 영화 예매 프로그램 (dict)활용
# #영화 종류를 나타내는 정수 1~3과 나이 입력, 영화와 가격은 다음과 같이 설정. 총 계산 출력
# #1: 액션영화 10,000원
# #2: 로맨틱 코미디 8,000원
# #3: 공포영화 9,000원
# #팝콘종류
# #1: 치즈팝콘 6,500원
# #2: 캬라멜 팝콘 5,000원
# #3: 일반 팝콘 5,000원
#[class]
cgv={
'movie':{
'movieList': ['1.액션영화','2.로맨틱코미디','3.공포영화'],
'moviePrice':[10000,8000,9000]
},
'popcorn':{
'popcornList': ['1.치즈팝콘','2.캬라멜팝콘','3.일반팝콘'],
'popcornPrice':[6000,5000,5000]
}
}
movie_choice=int(input(f"영화를 고르세요 [{cgv['movie']['movieList']}: "))-1
popcorn_choice=int(input(f"팝콘을 고르세요 [{cgv['popcorn']['popcornList']}: "))-1
print(f"고르신 영화는 {cgv['movie']['movieList'][movie_choice]}, 선택한 팝콘은 {cgv['popcorn']['popcornList'][popcorn_choice]}이며, "
f"총 금액은 {cgv['movie']['moviePrice'][movie_choice]+cgv['popcorn']['popcornPrice'][popcorn_choice]}원 입니다")
Dict의 주요 기능
1. get (key, default=None) - 특정 키에 해당하는 값을 반환 - 키가 사전에 없는 경우, default 값이 반환됨 (기본값은 None) 2. Keys() - 사전의 모든 키를 포함하는 뷰를 반환 3. values() - 사전의 모든 값을 포함하는 뷰를 반환 4. items() - 사전의 모든 키-값 쌍을 튜플로 포함하는 뷰를 반환
num=int(input("정수 입력:"))
if num > 0 :
print('양의 정수 입니다.')
elif num == 0:
print('0입니다')
else:
print('0 또는 음의 정수 입니다.')
(다중 elif 예시 1)
#유저에게 영어점수 입력 받고,
#100~90 A 입니다
#90~80 B 입니다
#80~70 C 입니다
#70 미만이면 재수강입니다
grade=int(input("영어점수는: "))
if grade > 90 :
print ('A 입니다')
elif grade > 80 :
print ('B 입니다')
elif grade > 70:
print ('C 입니다')
else:
print (' 재수강 입니다')
(파이썬 다중 if 예시 2)
#유저에게 비밀번호 설정 입력받고,
# 8글자보다 작으면 비밀번호가 8글자 이하입니다!
#만약에 비밀번호에 !없으면 특수문자가 없습니다.
# 다 통과 되면 비밀번호 완료!
pw=input("비밀번호 입력:")
print(pw.find("!"))
if len(pw) < 8:
print ("비밀번호가 8글자 이하입니다!")
elif "!" not in pw:
print ("특수문자가 없습니다")
else: print ('비밀번호 통과!')
(파이썬 다중 if 예시 3)
#유저에게 정수를 입력받고
#양의 홀수인지, 양의 짝수, 0, 음의 홀수, 음의 짝수 인지 알려주는 프로그램 만들기
if num > 0:
if num % 2 != 0:
print("양의 홀수")
else:
print("양의 짝수")
elif num == 0:
print("0 입니다.")
else:
if num % 2 != 0:
print("음의 홀수")
else:
print("음의 짝수")