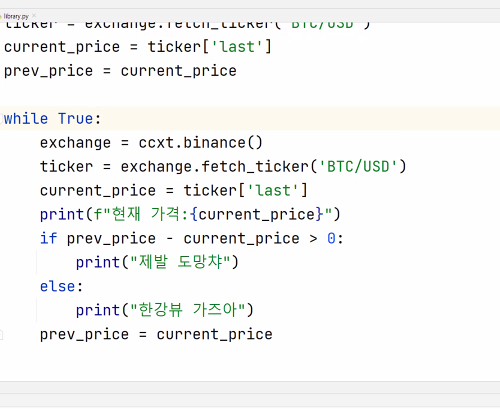
1. 라이브러리란 : 라이브러리는 특정 기능을 수행하는 함수나 클래스들의 모음임. 이들을 사용함으로써 개발 시간을 단축하고, 오류를 줄일 수 있음.
2. 파이참에서 라이브러리 설치하기 : 파이참에서는 프로젝트 설정을 통해 쉽게 라이브러리를 추가할 수 있음 ( File > Settings > Project : [프로젝트이름] > Python Interpreter ) 로 이동하여 필요한 라이브러리를 검색하고 설치할 수 있음
3. 라이브러리 사용 : 라이브러리를 설치한 후에는 import 구문을 사용하여 코드 내에서 해당 라이브러리를 호출하고, 그 기능을 사용할 수 있음.
import pandas as pd
from faker import Faker
fake = Faker('ko_KR')
print(fake.name())
carData = {
'carName' : ['k5','k7','avante','k3','tesla'],
'owner' : [fake.name() for i in range(5)]
}
print(carData)
#{'carName': ['k5', 'k7', 'avante', 'k3', 'tesla'], 'owner': ['나정호', '최현지', '김지우', '김유진', '이경수']}
df = pd.DataFrame(carData)
df.to_csv('car.csv',index=False)
결과 화면
(Pandas 예시 4)
import pandas as pd
import random
from datetime import *
from faker import Faker
fake = Faker('ko_KR')
movieList = ['웡카','시민덕희','도그맨','너의 이름은','라라랜드','상견니','외계인']
snackList = ['일반팝콘','캬라멜팝콘','치즈팝콘','구운오징어','나초','프레즐','핫도그']
drinkList = ['콜라','제로콜라','스프라이트','환타','에이드','물']
cgvData = {
'customers' : [fake.name() for i in range (500)],
'movies' : [random.choice(movieList) for i in range (500)],
'snack': [random.choice(snackList) for i in range(500)],
'drink': [random.choice(drinkList) for i in range(500)]
}
cgv_df = pd.DataFrame(cgvData) #위 cgv 데이터를 데이터프레임화 시키기
now = datetime.now()
cgv_df.to_csv(f"cgv.csv",index=False) #제목에 {now}가 안되서 그냥 cgv.